I’ve been redeploying processes into the AWS cloud at work.
After moving one of the backend processes for the dashboard into a micro instance, the CPU usage for the box went through the roof.
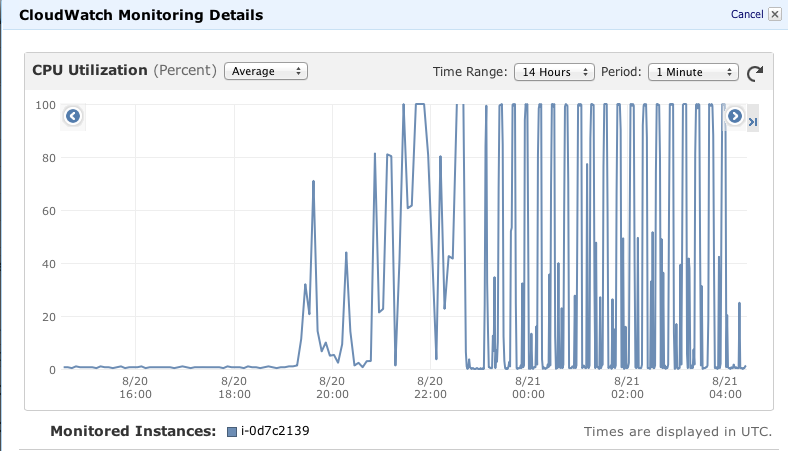
This was one of the oldest script in the project, and I’d never really instrumented any timing information.
I quickly went through and threw some StatsD timers in there, and came back the next day.
The worst offending function was the one that converted the result sets to HTML.
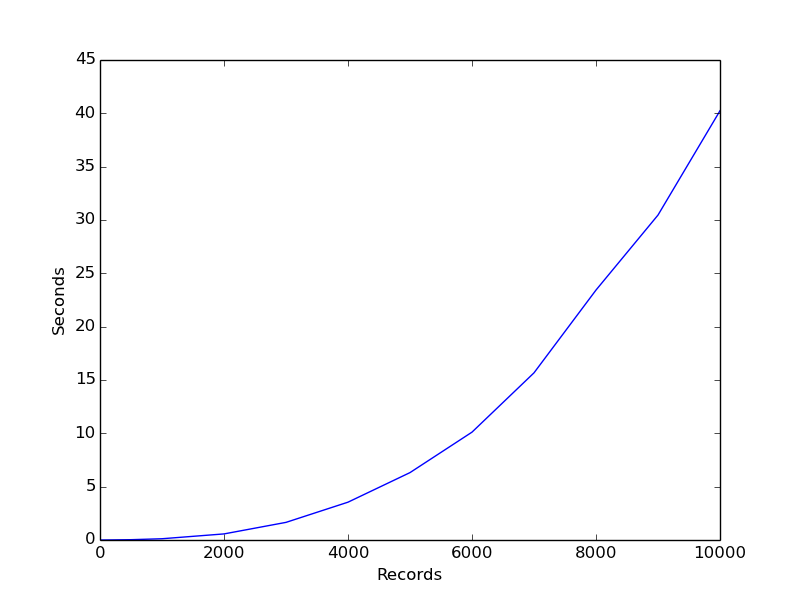 It’s been awhile since my algorithms class, but I’m pretty sure this is a bad growth curve.
It’s been awhile since my algorithms class, but I’m pretty sure this is a bad growth curve.
Looking at the function, it’s pretty simple:
def build_html(columns, rows, print_rowcount=False):
"""Returns the HTML table"""
columns = [title_caps(a) for a in columns]
parent_columns = []
out = "<thead><tr><th>"
out += "</th><th>".join(columns)
out += "</th></tr></thead><tbody>"
for i, row in enumerate(rows):
classes = []
styles = []
classes.append(("even", "odd")[i % 2])
out = out + '<tr class="%s" style="%s">' % (" ".join(classes), ";".join(styles))
#out = out + "<tr>"
if print_rowcount:
out = out + "<td>%d</td>" % (i + 1)
for j, r in enumerate(row):
val = r
if r is None:
val = ''
elif isinstance(val, float):
val = "%.2f" % val
else:
val = str(r)
out = out + "<td>" + val + "</td>"
out = out + "</tr>\n"
out = out + "</tbody>"
return out
I knew strings were immutable in python, and that += is the slowest way to concatenate them, but it didn’t sink home until I saw how bad they could be.
For my sample dataset of about 5000 rows on my reasonably powerful work computer, this function took 46 seconds!
Switching to .join() took it down to about 4 seconds:
out = "<thead><tr><th>"
out += "</th><th>".join(columns)
out += "</th></tr></thead><tbody>"
for i, row in enumerate(rows):
classes=[]
styles=[]
classes.append(("even", "odd")[i % 2])
out += '<tr class="%s" style="%s"><td>' % (" ".join(classes), ";".join(styles))
vals = []
for j, r in enumerate(row):
val = str(r)
vals.append(val)
out += "</td><td>".join(vals)
out += "</td></tr>\n"
return out
That was pretty good, but I figured cStringIO would be even faster.
out = StringIO()
out.write("<thead><tr><th>")
out.write("</th><th>".join(columns))
out.write("</th></tr></thead><tbody>")
for i, row in enumerate(rows):
classes=[]
styles=[]
classes.append(("even", "odd")[i % 2])
out.write('<tr class="%s" style="%s"><td>' % (" ".join(classes), ";".join(styles)))
vals = []
for j, r in enumerate(row):
val = str(r)
# Type checking ...
vals.append(val)
out.write("</td><td>".join(vals))
out.write("</td></tr>\n")
return out.getvalue()
That dropped the total time down to .22 seconds.
Interestingly, the next thing I tried was
out = StringIO()
for i, row in enumerate(rows):
out.write("<tr>")
vals = []
for j, r in enumerate(row):
val = str(r)
# Type checking ...
out.write("<td>%s</td>" % val)
out.write("</tr>")
That actually made the time worse. So I stopped & figured that I was hitting the point of diminishing returns.